I first registered BrentOzar.com way back in May 2001.
Over the years, some things in databases have changed a lot, but some things still remain the same.
Every year, people get handed applications and databases, and they’re told, “The back end is Microsoft SQL Server. Figure it out and make it work – faster.”
Every year, people struggle. They try to learn as much as they can via Google, free blog posts and webcasts, and their peers. They put the pieces together as best they can, but eventually, they hit a wall.
And that’s where my classes come in.
The sale ends May 31. To get these deals, you have to check out online through our e-commerce site by clicking the buttons above. During the checkout process, you’ll be offered the choice of a credit card or buy now pay later.
Can we pay via bank transfer, check, or purchase order? Yes, but only for 10 or more seats for the same package, and payment must be received before the sale ends. Email us at Help@BrentOzar.com with the package you want to buy and the number of seats, and we can generate a quote to include with your check or wire. Make your check payable to Brent Ozar Unlimited and mail it to 9450 SW Gemini Drive, ECM #45779, Beaverton, OR 97008. Your payment must be received before we activate your training, and must be received before the sale ends. Payments received after the sale ends will not be honored. We do not accept POs as payment unless they are also accompanied with a check. For a W9 form: https://downloads.brentozar.com/w9.pdf
Can we send you a form to fill out? No, to keep costs low during these sales, we don’t do any manual paperwork. To get these awesome prices, you’ll need to check out through the site and use the automatically generated PDF invoice/receipt that gets sent to you via email about 15-30 minutes after your purchase finishes. If you absolutely need us to fill out paperwork or generate a quote, we’d be happy to do it at our regular (non-sale) prices – email us at Help@BrentOzar.com.

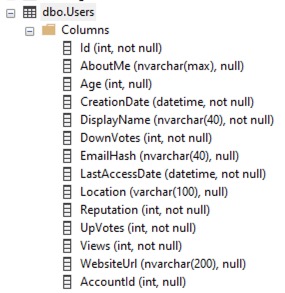 For example, in this week’s query challenge, the Users table has a lot of really hot columns that change constantly, like LastAccessDate, Reputation, DownVotes, UpVotes, and Views. I don’t want to log those changes at all, and I don’t want my logging to slow down the updates of those columns.
For example, in this week’s query challenge, the Users table has a lot of really hot columns that change constantly, like LastAccessDate, Reputation, DownVotes, UpVotes, and Views. I don’t want to log those changes at all, and I don’t want my logging to slow down the updates of those columns.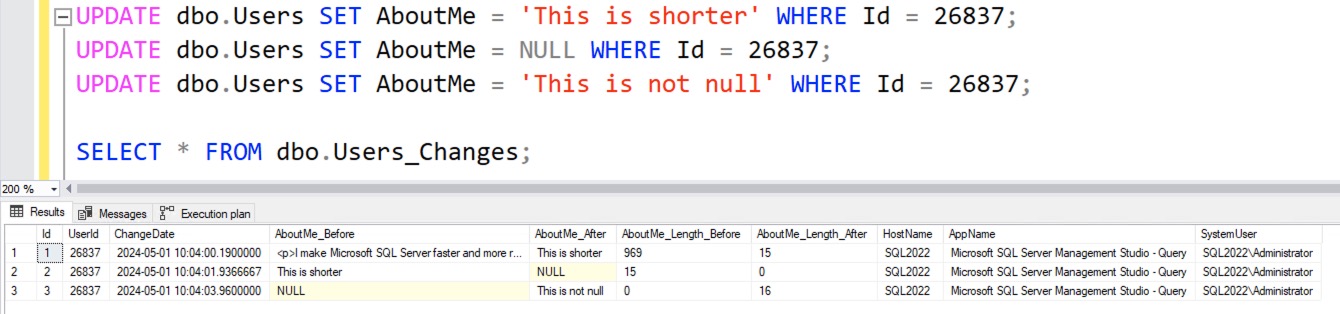


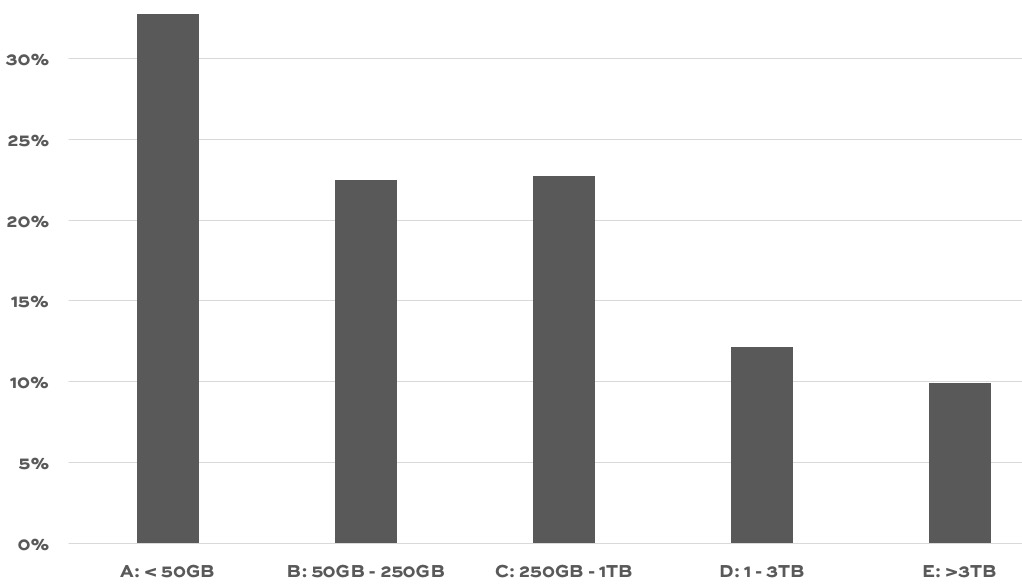
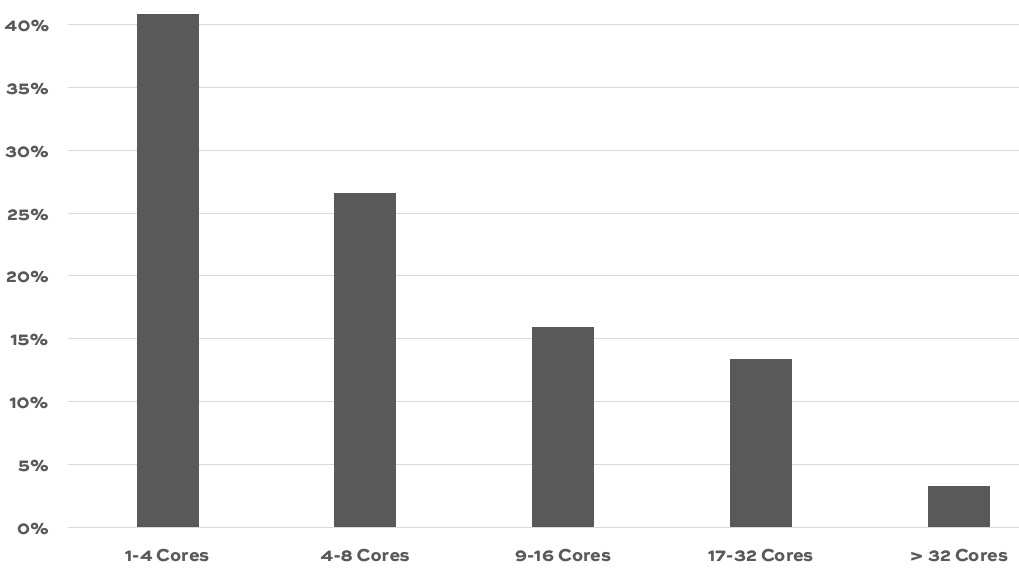
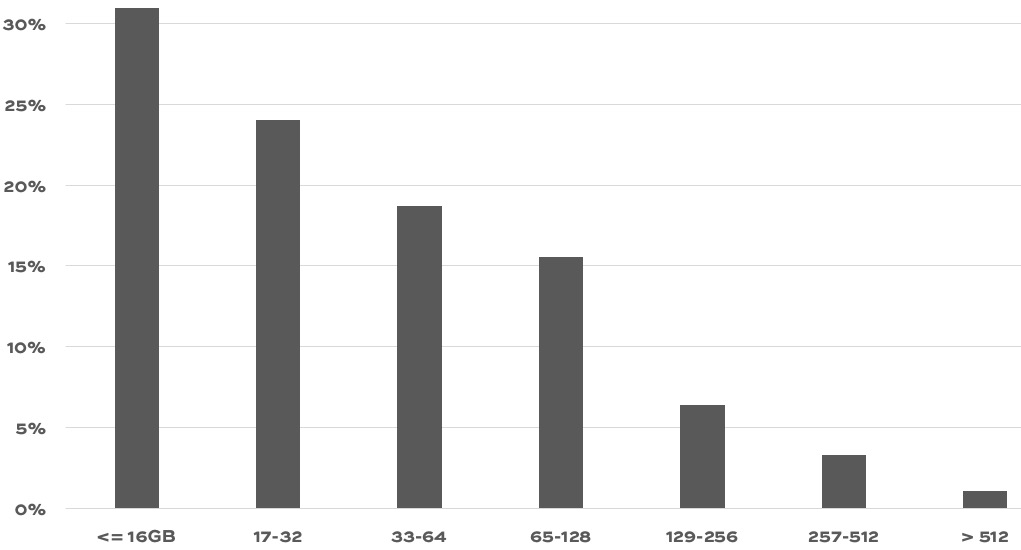
 If your company is hiring, leave a comment. The rules:
If your company is hiring, leave a comment. The rules: On November 4 in Seattle, I’m presenting a new pre-conference workshop!
On November 4 in Seattle, I’m presenting a new pre-conference workshop!